様々な国や地域の雨滴粒径分布の解析
はじめに
雨滴粒径分布は、大気中の単位体積内における雨滴の数濃度と粒径分布を記述する。これは、大気中のマイクロ波信号の伝播をモデル化(通信や気象レーダーの遠隔測定校正に不可欠)、数値気象予測モデルにおける微物理スキームの改善、および地表面プロセス(降雨の捕捉、土壌侵食)の理解に不可欠である。世界中の研究者は、雨滴粒径分布の時空間的な変動を理解するため、雨滴粒径分布を記録する装置の一つであるディスドロメーターを配備してきた。気象サービス・国家機関・大学研究グループなどにより、数多くの特別観測が実施されてきた。しかしながら、現状、それらのデータのほんの一部にしか容易にアクセスすることは出来ない。データは多様な形式で保存されており、それらの共有・解析・比較・再利用は、多くの場合困難となっている。加えて、雨滴粒径分布を処理するソフトウェアは極めて限られており、公開されているものはほとんど無い (私の知る限り、PyDSD ぐらい)。
近年、以上の課題に対応する具体として、DISDRODB というソフトウェアの開発が GitHub 上で進められている。このソフトウェアは、近年進められているオープンサイエンスのベストプラクティスに従って、ディスドロメーターデータをダウンロード・解析・アーカイブするためのツールセットを提供する。DISDRODB の主な目的として、1. 世界中のディスドロメーターデータから分散型アーカイブを作成すること、2. 科学コミュニティ全体でのデータ交換を促進すること、3. 利用可能なデータとディスドロメーターセンサーの種類を文書化すること、4. ディスドロメーターデータを処理するための共通フレームワークを提供すること、5. 雨滴粒径分布の時空間的変動を全球規模で研究するための科学的な解析ツールを開発すること、6. 粒径分布モデルとそのアルゴリズムの開発・共有・改善を行うコミュニティを構築すること、が掲げられている。
今回は、この DISDRODB の利用方法を紹介する。
DISDRODB
2025年6月11日現在、DISDRODB の最新バージョンは 0.1.2 である。この最新版を今回利用する。
まず、ドキュメント に従って、環境を構築する。その後、ソフトウェアをインストールする。使用した環境はSpectral-Bin-Microphysics-Modelで使用したものと同じ。今回は miniconda を用いた。具体的なコマンドは以下。
conda create --name disdrodb --no-default-packages
conda activate disdrodb
conda install -c conda-forge disdrodb matplotlib
conda clean -tp次に、DISDRODB のアーカイブ保存ディレクトリとメタデータ格納ディレクトリをそれぞれ作成する。今回は、作業ディレクトリ直下に data/ というディレクトリを作成し、その中に作成した。アーカイブ保存ディレクトリは空のディレクトリを作成するだけで良い。一方、メタデータについては、別の GitHub リポジトリを使用する。具体的なコマンドは下記。
mkdir data/DISDRODB
cd data/
git clone https://github.com/ltelab/DISDRODB-METADATA.git
cd ../そして、下記の Python スクリプトを作成する。DISDRODB では、bash で実行用のコマンドラインインターフェースと Python (主に Jupyter notebook 等) 用の関数の二種が用意されている。私が試した限りでは、後者にバグがあり、出力される値が極端に小さくなってしまうようである。このため、前者のコマンドラインインターフェースを主として用いた (なので、Python スクリプト内で subprocess.run を用いている)。
#!/usr/bin/env python
# coding: utf-8
# Preparation
import subprocess
import disdrodb
print("disdrodb: ", disdrodb.__version__)
# Define archive directories
metadata_archive_dir = "data/DISDRODB-METADATA/DISDRODB"
data_archive_dir = "data/DISDRODB"
disdrodb.define_configs(metadata_archive_dir=metadata_archive_dir, data_archive_dir=data_archive_dir) # これは初回だけで良い。実行後、~/.config_disdrodb.yml が作成される。
print("DISDRODB Metadata Archive Directory: ", disdrodb.get_metadata_archive_dir())
print("DISDRODB Data Archive Directory: ", disdrodb.get_data_archive_dir())
# Check metadata
disdrodb.available_stations(available_data=True)
disdrodb.check_metadata_archive()
# Define station arguments
data_source = "EPFL"
campaign_name = "HYMEX_LTE_SOP3"
station_name = "10"
# List all files
filepaths = disdrodb.find_files(
product="RAW",
data_source=data_source,
campaign_name=campaign_name,
station_name=station_name,
)
print(filepaths)
# Read metadata
metadata = disdrodb.read_station_metadata(
metadata_archive_dir=metadata_archive_dir,
data_source=data_source,
campaign_name=campaign_name,
station_name=station_name,
)
print(metadata)
# Generate DISDRODB L0 product
subprocess.run(["disdrodb_run_l0_station", data_source, campaign_name, station_name, "--force", "True", "--verbose", "True", "--parallel", "False"])
# Generate DISDRODB L1 product
subprocess.run(["disdrodb_run_l1_station", data_source, campaign_name, station_name, "--force", "True", "--verbose", "True", "--parallel", "False"])
# Generate DISDRODB L2 product
subprocess.run(["disdrodb_run_l2e_station", data_source, campaign_name, station_name, "--force", "True", "--verbose", "True", "--parallel", "False"])
subprocess.run(["disdrodb_run_l2m_station", data_source, campaign_name, station_name, "--force", "True", "--verbose", "True", "--parallel", "False"])DISDRODB では、メタデータとデータ本体とが別々に管理される。メタデータは、国・観測プロジェクト名・サイト名の階層で管理され、地点の位置情報やデータの期間、測器の種類や読み込み方法、データの取得先等が記述される。詳細はこちらを参照されたし。このメタデータに基づいて、データの位置情報や reader、データの期間・取得先等が機械的に定まるようになっている。今回は、公開されているスイスのデータを用いた。データ本体は、前述のメタデータに取得先が記述される。しかし、機関によってはデータを無条件で公開出来ない場合があり、その場合はメタデータの取得先が空欄になっている。メタデータとしてデータがあることは公開するけれども、実際にデータを使用する場合には、利用者が直接問い合わせてデータを取得する必要があるだろう。ただ、このデータの有無が分かるだけでも有益な情報となる。この点こそが、DISDRODB の目的の一つである。
出力されるプロダクトは、大きく分けて三種類ある。Level 0 (L0) プロダクト、Level 1 (L1) プロダクト、そして Level 2 (L2) プロダクトである。L0 プロダクトは、主に測器から出力されるオリジナルデータ (RAW データ) のフォーマットを整えるために作成される。DISDRODB で推奨される品質管理もこの L0 プロダクト作成時に実施される。最終的に L0C と呼ばれるプロダクトが生成され、後続の L1 プロダクトの作成に使用される。出力データのフォーマットは、CF 規約及び ACDD 規約に則った NetCDF である。L1 プロダクトは、L0 プロダクトで格納された粒径分布にフィルター処理を実施し、基本的な統計量を計算する。出力形式は、上記と同じ NetCDF。L2 プロダクトは、L1 プロダクトの粒径分布から各種粒径分布パラメーターを計算する。散乱計算によるレーダーパラメーターの計算モジュールも実装されているが、開発者によると Python 版 T-Matrix モジュールの修正中であり現在は利用不可とのことである。こちらも出力形式は上記と同じ NetCDF 形式である。
可視化
出力されたデータは xarray dataset として構造化されているので、そのデータ構造と共にデータを確認していく。
L0 プロダクト
データ読み込み
import disdrodb
ds = disdrodb.open_dataset(
product="L0C",
# Station arguments
data_source=data_source,
campaign_name=campaign_name,
station_name=station_name,
)
print(ds)データ構造
<xarray.Dataset> Size: 1GB
Dimensions: (time: 248960, diameter_bin_center: 32,
velocity_bin_center: 32, crs: 1)
Coordinates: (12/15)
* diameter_bin_center (diameter_bin_center) float64 256B 0.062 ...
diameter_bin_lower (diameter_bin_center) float64 256B dask.array<chunksize=(32,), meta=np.ndarray>
diameter_bin_upper (diameter_bin_center) float64 256B dask.array<chunksize=(32,), meta=np.ndarray>
diameter_bin_width (diameter_bin_center) float64 256B dask.array<chunksize=(32,), meta=np.ndarray>
* velocity_bin_center (velocity_bin_center) float64 256B 0.05 ....
velocity_bin_lower (velocity_bin_center) float64 256B dask.array<chunksize=(32,), meta=np.ndarray>
... ...
longitude float64 8B 4.499
altitude float64 8B 496.0
* crs (crs) <U5 20B 'WGS84'
sample_interval int64 8B 30
* time (time) datetime64[ns] 2MB 2013-09-01 ... ...
time_qc (time) float64 2MB dask.array<chunksize=(2880,), meta=np.ndarray>
Data variables: (12/16)
raw_drop_concentration (time, diameter_bin_center) float32 32MB dask.array<chunksize=(2880, 32), meta=np.ndarray>
raw_drop_average_velocity (time, diameter_bin_center) float32 32MB dask.array<chunksize=(2880, 32), meta=np.ndarray>
raw_drop_number (time, diameter_bin_center, velocity_bin_center) float32 1GB dask.array<chunksize=(2880, 32, 32), meta=np.ndarray>
rainfall_rate_32bit (time) float32 996kB dask.array<chunksize=(2880,), meta=np.ndarray>
rainfall_accumulated_32bit (time) float32 996kB dask.array<chunksize=(2880,), meta=np.ndarray>
weather_code_synop_4680 (time) float32 996kB dask.array<chunksize=(2880,), meta=np.ndarray>
... ...
number_particles (time) float64 2MB dask.array<chunksize=(2880,), meta=np.ndarray>
sensor_temperature (time) float32 996kB dask.array<chunksize=(2880,), meta=np.ndarray>
sensor_heating_current (time) float32 996kB dask.array<chunksize=(2880,), meta=np.ndarray>
sensor_battery_voltage (time) float32 996kB dask.array<chunksize=(2880,), meta=np.ndarray>
sensor_status (time) float32 996kB dask.array<chunksize=(2880,), meta=np.ndarray>
rainfall_amount_absolute_32bit (time) float32 996kB dask.array<chunksize=(2880,), meta=np.ndarray>
Attributes: (12/62)
data_source: EPFL
campaign_name: HYMEX_LTE_SOP3
station_name: 10
sensor_name: PARSIVEL
reader: EPFL/HYMEX_LTE_SOP3
raw_data_glob_pattern: *.dat.gz
... ...
Conventions: CF-1.10, ACDD-1.3
featureType: timeSeries
disdrodb_processing_date: 2025-06-11 20:32:21
disdrodb_product_version: V0
disdrodb_software_version: V0.1.2
disdrodb_product: L0CD-V 分布
import matplotlib.pyplot as plt
from matplotlib.colors import LogNorm
cmap = plt.get_cmap("cubehelix_r")
cmap.set_under(alpha=0)
ds.raw_drop_number.sum(dim="time").plot.pcolormesh(
x="diameter_bin_center", y="velocity_bin_center",
cmap=cmap, norm=LogNorm(1, 100000)
)
plt.xlim(0,10)
plt.ylim(0,20)
plt.show()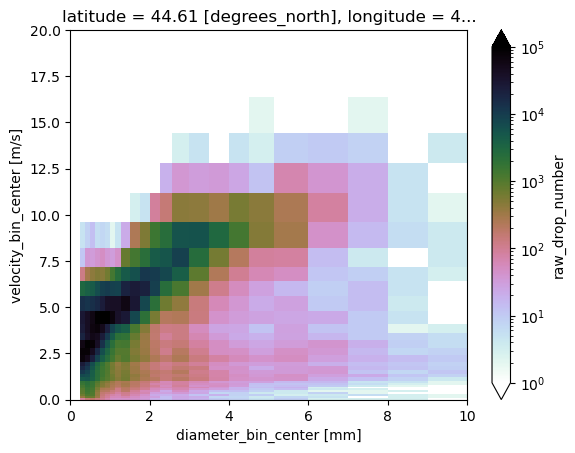
L1 プロダクト
データ読み込み
import disdrodb
ds = disdrodb.open_dataset(
product="L1",
# Station arguments
data_source=data_source,
campaign_name=campaign_name,
station_name=station_name,
)
print(ds)データ構造
<xarray.Dataset> Size: 1GB
Dimensions: (time: 248960, diameter_bin_center: 23,
velocity_bin_center: 27)
Coordinates: (12/14)
latitude float64 8B 44.61
longitude float64 8B 4.499
altitude float64 8B 496.0
sample_interval int64 8B 30
* diameter_bin_center (diameter_bin_center) float64 184B 0.312 ... 9.5
diameter_bin_lower (diameter_bin_center) float64 184B dask.array<chunksize=(23,), meta=np.ndarray>
... ...
* velocity_bin_center (velocity_bin_center) float64 216B 0.05 ... 10.4
velocity_bin_lower (velocity_bin_center) float64 216B dask.array<chunksize=(27,), meta=np.ndarray>
velocity_bin_upper (velocity_bin_center) float64 216B dask.array<chunksize=(27,), meta=np.ndarray>
velocity_bin_width (velocity_bin_center) float64 216B dask.array<chunksize=(27,), meta=np.ndarray>
* time (time) datetime64[ns] 2MB 2013-09-01 ... 2013-...
time_qc (time) float64 2MB dask.array<chunksize=(2880,), meta=np.ndarray>
Data variables:
fall_velocity (time, diameter_bin_center) float64 46MB dask.array<chunksize=(2880, 23), meta=np.ndarray>
drop_number (time, diameter_bin_center, velocity_bin_center) float64 1GB dask.array<chunksize=(2880, 23, 27), meta=np.ndarray>
drop_counts (time, diameter_bin_center) float64 46MB dask.array<chunksize=(2880, 23), meta=np.ndarray>
Dmin (time) float64 2MB dask.array<chunksize=(2880,), meta=np.ndarray>
Dmax (time) float64 2MB dask.array<chunksize=(2880,), meta=np.ndarray>
N (time) float64 2MB dask.array<chunksize=(2880,), meta=np.ndarray>
Nremoved (time) float64 2MB dask.array<chunksize=(2880,), meta=np.ndarray>
Nbins (time) float32 996kB dask.array<chunksize=(2880,), meta=np.ndarray>
Nbins_missing (time) float64 2MB dask.array<chunksize=(2880,), meta=np.ndarray>
Nbins_missing_fraction (time) float64 2MB dask.array<chunksize=(2880,), meta=np.ndarray>
Nbins_missing_consecutive (time) float64 2MB dask.array<chunksize=(2880,), meta=np.ndarray>
Attributes: (12/62)
data_source: EPFL
campaign_name: HYMEX_LTE_SOP3
station_name: 10
sensor_name: PARSIVEL
reader: EPFL/HYMEX_LTE_SOP3
raw_data_glob_pattern: *.dat.gz
... ...
Conventions: CF-1.10, ACDD-1.3
featureType: timeSeries
disdrodb_processing_date: 2025-06-11 20:34:19
disdrodb_product_version: V0
disdrodb_software_version: V0.1.2
disdrodb_product: L1粒径と粒径の落下速度の二次元ヒストグラム
import matplotlib.pyplot as plt
from matplotlib.colors import LogNorm
cmap = plt.get_cmap("cubehelix_r")
cmap.set_under(alpha=0)
ds.raw_drop_number.sum(dim="time").plot.pcolormesh(
x="diameter_bin_center", y="velocity_bin_center",
cmap=cmap, norm=LogNorm(1, 100000)
)
plt.xlim(0,10)
plt.ylim(0,20)
plt.show()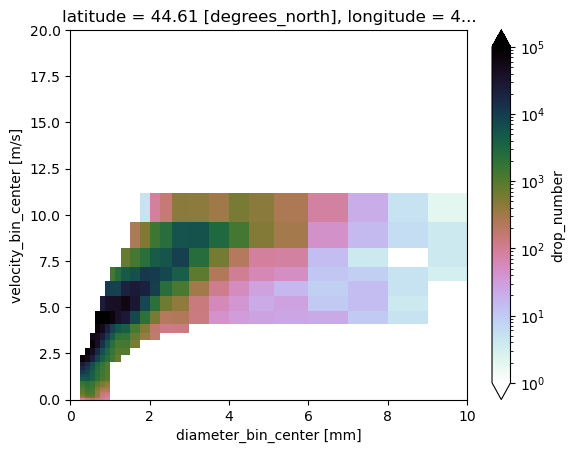
L2 プロダクト
データ読み込み
import disdrodb
ds = disdrodb.open_dataset(
data_archive_dir=data_archive_dir,
product="L2M",
# Station arguments
data_source=data_source,
campaign_name=campaign_name,
station_name=station_name,
# L2M product options
product_kwargs={"model_name": "NGAMMA_GS_LOG_ND_MAE", "sample_interval": 60, "rolling": False},
)
print(ds)データ構造
<xarray.Dataset> Size: 7MB
Dimensions: (time: 15274, velocity_method: 2)
Coordinates:
sample_interval int64 8B 60
latitude float64 8B 44.61
longitude float64 8B 4.499
altitude float64 8B 496.0
* time (time) datetime64[ns] 122kB 2013-0...
* velocity_method (velocity_method) <U17 136B 'fall_...
Data variables: (12/32)
Nt (time, velocity_method) float32 122kB dask.array<chunksize=(47, 2), meta=np.ndarray>
R (time, velocity_method) float64 244kB dask.array<chunksize=(47, 2), meta=np.ndarray>
P (time, velocity_method) float32 122kB dask.array<chunksize=(47, 2), meta=np.ndarray>
M0 (time, velocity_method) float64 244kB dask.array<chunksize=(47, 2), meta=np.ndarray>
M1 (time, velocity_method) float32 122kB dask.array<chunksize=(47, 2), meta=np.ndarray>
M2 (time, velocity_method) float32 122kB dask.array<chunksize=(47, 2), meta=np.ndarray>
... ...
relative_max_error (time, velocity_method) float64 244kB dask.array<chunksize=(47, 2), meta=np.ndarray>
total_number_concentration_difference (time, velocity_method) float64 244kB dask.array<chunksize=(47, 2), meta=np.ndarray>
kl_divergence (time, velocity_method) float64 244kB dask.array<chunksize=(47, 2), meta=np.ndarray>
max_deviation (time, velocity_method) float64 244kB dask.array<chunksize=(47, 2), meta=np.ndarray>
max_relative_deviation (time, velocity_method) float64 244kB dask.array<chunksize=(47, 2), meta=np.ndarray>
diameter_mode_deviation (time, velocity_method) float64 244kB dask.array<chunksize=(47, 2), meta=np.ndarray>
Attributes: (12/64)
data_source: EPFL
campaign_name: HYMEX_LTE_SOP3
station_name: 10
sensor_name: PARSIVEL
reader: EPFL/HYMEX_LTE_SOP3
raw_data_glob_pattern: *.dat.gz
... ...
disdrodb_processing_date: 2025-06-11 20:48:45
disdrodb_product_version: V0
disdrodb_software_version: V0.1.2
disdrodb_product: L2M
rolled: False
disdrodb_psd_model: NormalizedGammaPSDimport matplotlib.pyplot as plt
from matplotlib.colors import LogNorm
plt.scatter(ds.Dm[:,1], ds.Nw[:,1], c=ds.R[:,1], norm=LogNorm(), cmap=plt.get_cmap("cubehelix_r"))
plt.ylim(1,1000000)
plt.xlim(0,6)
plt.title('$D_\mathrm{m}$-$N_\mathrm{w}$ relation with $R$')
plt.ylabel('$N_\mathrm{w}$ (mm$^{-1}$ m$^{-3}$)')
plt.xlabel('$D_\mathrm{m}$ (mm)')
plt.yscale('log')
plt.grid()
plt.colorbar(extend='max').set_label('$R$ (mm hr$^{-1}$)')
plt.clim(1,100)
plt.show()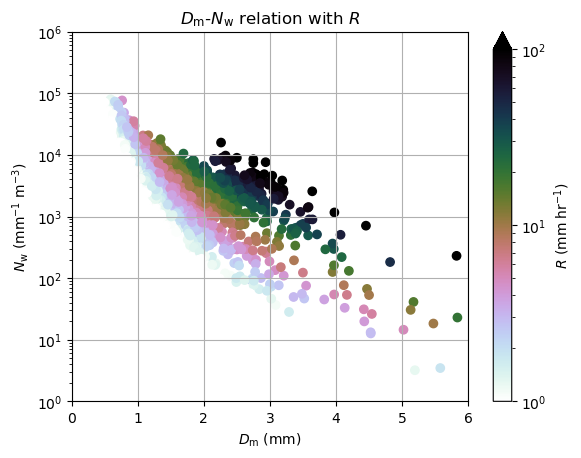
おわりに
今回は、様々な国や地域の雨滴粒径分布を解析するオープンソースソフトウェアについて紹介した。
参考文献
更新履歴
- 2025-06-11: 初稿
Miscellaneous — Jun 11, 2025
Made with ❤ and at Japan.